MiSoC Co-Is Paul Clarke and Spyros Samothrakis, together with post-doctoral researcher Annalivia Polselli and PhD student/research officer Damian Machlanski, are conducting research into the use of machine learning (ML) in the social sciences.
ML is an exciting field at the interface of artificial intelligence and computer science. It is concerned with developing algorithms for solving prediction (e.g. regression or classification) problems. These algorithms work best whenever Big Data are available and the goal is prediction or classification, but ML also has great potential for use in quantitative social science. In particular, the powerful algorithms of supervised ML allow researchers to fit, or learn, algorithms that accurately predict an outcome variable when it is a high-dimensional or non-linear function of predictor variables, but without the analyst having to specify a functional form for this relationship.
This is important because social scientists use standard statistical and econometric parametric models for the relationship between predictors and outcomes. These are much simpler and less flexible than ML algorithms but, crucially, have parameters with clear scientific meaning which enable us to test scientific hypotheses. However, predictions based on this sort of model could potentially be much less accurate than those based on ML algorithms.
The focus of this strand so far has been on ML for the causal analysis of observational data. This combines the benefits of standard statistics/econometrics in that we target a clearly defined and interpretable parameter like the average treatment effect (ATE) or the conditional average treatment effect (CATE), but often have to correctly estimate relationships – referred to as nuisance parameters – about which we have no substantive interest or theoretical guidance but which are, nonetheless, important to ensuring that bias (systematic errors) is reduced and precision increased (i.e. the impact of random errors decreased).
Hence, using learners from ML can potentially improve the accuracy of the estimates we obtain from observational data and so reduce the bias in our estimates. It also makes feasible previously infeasible tasks like causal discovery.
Our programme of research is currently investigating the use of various types of learners to see how effective these are at reducing bias compared with conventional approaches.
Improved estimation of conditional average treatment effects. When we estimate the causal effects of an exposure for different types of people – CATEs – then bias will be introduced. This is because, unlike in randomised experiments, the number of people exposed can be very different to the number unexposed, and this imbalance can differ greatly between different groups of people (see the figure below).
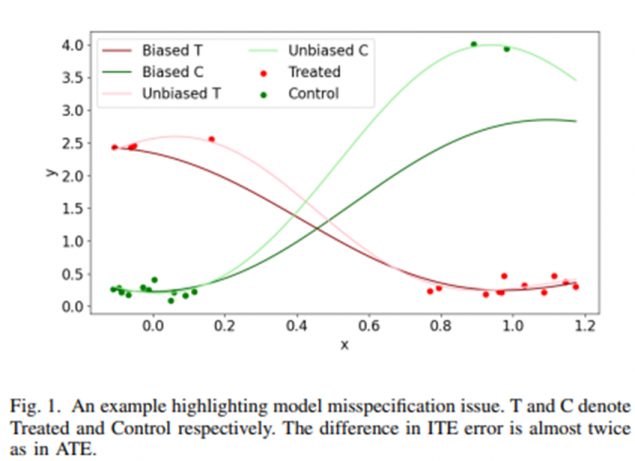
This can lead to large bias even if the analyst has controlled for all possible sources of confounding. To address this problem, we proposed a novel ML technique, based on generative trees and Gaussian mixture models, to reduce bias by undersmoothing these differences and using data augmentation to correct the imbalance, and in doing so produce more accurate estimates than standard methods, and even existing state-of-the-art ML algorithms (including those based on double machine learning).
Read a summary here or read the paper in IEEE Access by Machlanski et al here.
Causal estimation using panel data. Double Machine Learning (DML) was developed to allow ML predictions of nuisance parameters to be incorporated into statistical/econometric estimation. We have used DML to develop panel models for static panel (or longitudinal) data for estimating ATEs when the nuisance parameters – here the effects of the confounding variables – are unknown and potentially non-linear, and there is unobserved confounding from omitted variables (provided these variables are fixed over time). Standard panel methods implicitly require the nuisance parameters to be linear. We develop methods for estimating the ATE based on adapting the within-group, first-difference and correlated random effects estimators for linear panel models, and also investigate the performance of different ML algorithms for estimating the nuisances. The results of a simulation study we carried out for the correlated random effects (CRE) estimator (see Figure 2 below) show that bias is reduced even when the truth is highly non-linear and discontinuous (DGP3).
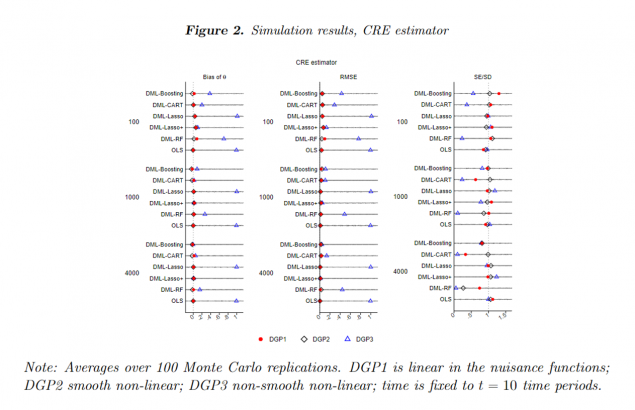
Read more in our paper (in press with The Econometrics Journal) by Polselli and Clarke here
The role of hyperparameter selection in causal analysis and Causal Discovery. ML algorithms are more powerful than traditional statistical estimation but are also far more complex and so need more care and attention from the analyst. This manifests itself in choosing the right hyperparameters for an algorithm, a procedure known as hyperparameter tuning. A poor choice of hyperparameters can lead to inaccurate predictions and so fail to realize an algorithm’s potential.
CATE estimation: In the case of estimating CATEs, we carried out an extensive empirical study in which it was found that hyperparameter choice was actually more important than the CATE estimator or ML algorithms chosen by the analyst. We also found that not performing tuning and instead deferring to pre-set, or default, hyperparameter values (e.g. suggested by code packages) significantly harms estimation performance and prevents estimators from reaching their full potential. The main findings showcasing performance differences depending on hyperparameter choices are summarised in the figure below.
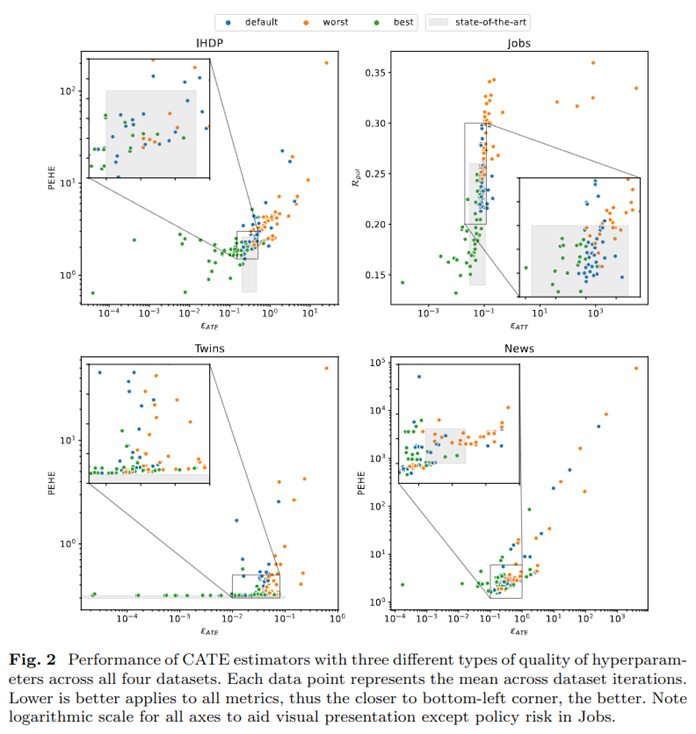
Read a summary here or read our (under review) paper by Machlanski et al here
Structure (or Causal) Discovery: Structure discovery does not involve estimating causal effects but rather the more complicated task of learning the true structure of the graphical representation of the unknown process that generated the data, telling us the causal antecedents of each variable in our dataset. Structure discovery has been shown to be theoretically possible under reasonable assumptions about the truth, and various discovery algorithms have been proposed. In practice, the performance of these algorithms has been shown to be acceptable for small (fewer than ten) variables but not otherwise, not least because of the computational burden of the algorithms. We investigated the role of hyperparameter choice plays in achieving state-of-the-art performance using a detailed simulation study. Some results showing the performance of the different methods for different hyperparameter choices are shown in Figure 3 (below).
We investigated the role of hyperparameter choice in achieving state-of-the-art performance as well as robustness of different algorithms to hyperparameter selection. Using a detailed simulation study, we found that: a) even after tuning, some algorithms still perform better than others under specific data conditions, and b) algorithms vary in robustness to poor hyperparameter choices. Some results showing how significantly the performance of different methods can vary depending on different hyperparameter choices as well as different data settings are shown in the figure below.
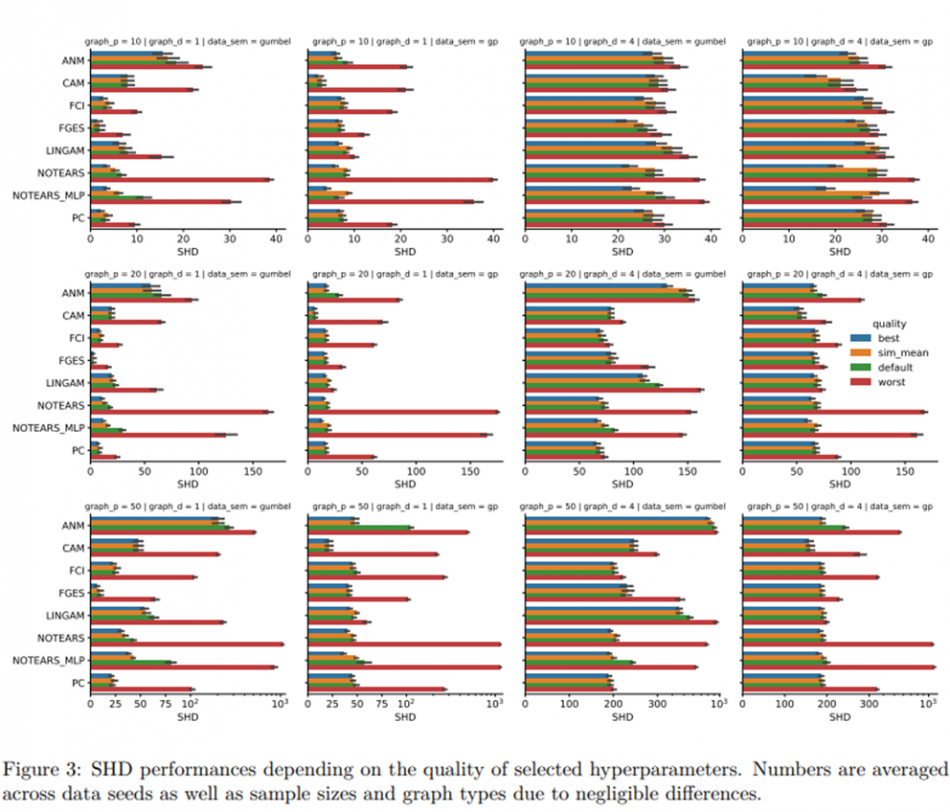
Read a summary here or read the full paper in Proceedings of the Third Conference on Causal Learning and Reasoning by Machlanski et al here.
On-going and future work:
We are looking at extending the applicability of DML to other panel data settings, such as, dynamic panel data. We are also considering the extension of DML to heterogeneous treatment effects in interactive regression models with fixed effects. This will allow us to estimate the intensity of the effect of a policy intervention among groups with the potential to help policy-makers target interventions to those who need it the most in the most effective way. Finally, we will allow the use of instrumental variables when the strict exogeneity assumption is violated, which is always the case in many applications in social sciences.
Another research direction we are excited about is bringing the latest and most powerful ML predictors to panel data in the form of neural networks, with a particular emphasis on making these accessible to social scientists. Furthermore, we look at bridging the gap between panel data and reinforcement learning (a strand of ML) by exploiting similarities between the two areas. This path can open an unexplored before territory of new highly adaptable causal estimators for panel data.